Clust solves what we perceive as the biggest problem in gene co-expression clustering.
Clust extracts tight and distinct clusters of co-expressed genes from one or more gene expression datasets. Clust automatically filters out genes that do not form quality clusters.
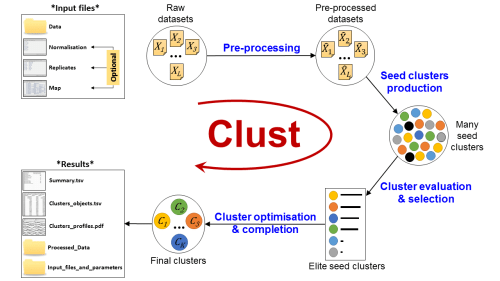
Clust follows an automatic pipeline of sophisticated steps of draft clustering, cluster evaluation and selection, and cluster optimisation and completion (summarised in the figure below).
Clust is freely available as easy-to-install easy-to-use package at:
https://github.com/BaselAbujamous/clust
Clust outperforms mainstream gene expression methods as demonstrated by comparison over 100 datasets assessed by eight different cluster validation metrics. Details are in our pre-print manuscript.
If you use clust, please cite:
Basel Abu-Jamous and Steven Kelly (2018) Clust: automatic extraction of optimal co-expressed gene clusters from gene expression data. Genome Biology 19: 172; doi: https://doi.org/10.1186/s13059-018-1536-8.